NASDAQ Level 3 Order Data
NASDAQ provides dumps of real-time orders for some trading days free of charge. This guide will show you how to parse it and import it into CedarDB for analysis.
What is order data?
High-frequency traders, quantitative analysts, and institutional investors depend on knowing the exact state of the market at any time to base their investment decisions on. To this end, exchanges like the NASDAQ or NYSE offer live market data which interested parties can then consume with specialized tools to recreate the exchange state, the so-called order book in real time.
The holy grail of this live market data is the Level III order book data. It not only shows the current market price of any given stock but all orders that are currently active. The exact format of orders differ between exchanges, but it generally has the following format:
| ID | Ticker | Timestamp | Side | Quantity | Price | PrevOrderId |
|---|---|---|---|---|---|---|
| 1 | AAPL | 9:30:00:000 | BUY | 5 | 225.49 | null |
| 2 | AAPL | 9:30:00:010 | SELL | 2 | 225.52 | null |
In this example, order 1 wants to buy 5 apple shares at $225.49 and order 2 wants to sell at $225.52. Since they don’t agree on a price, they aren’t matched and both pending orders are active in the system at the same time.
Whenever orders are matched, we get an execution event with roughly the following format:
| Timestamp | OrderID | Quantity |
|---|---|---|
| 9:30:00:100 | 1 | 2 |
It seems like someone took the issuer of order 1 up on their offer and bought 2 shares for a price of $225.49. The state of the order book now looks like this:
| ID | Ticker | Timestamp | Side | Quantity | Price | PrevOrderId |
|---|---|---|---|---|---|---|
| 1 | AAPL | 9:30:00:000 | BUY | 3 | 225.49 | null |
| 2 | AAPL | 9:30:00:010 | SELL | 2 | 225.52 | null |
The market price of AAPL is now $225.49 since this was the last price at which it was actively traded.
Issuer of order number 2 now notices nobody wants to buy at their price and reduces their ask:
| ID | Ticker | Timestamp | Side | Quantity | Price | PrevOrderId |
|---|---|---|---|---|---|---|
| 1 | AAPL | 9:30:00:000 | BUY | 3 | 225.49 | null |
| 3 | AAPL | 9:31:00:000 | SELL | 2 | 225.50 | 2 |
As you can see, the updated order is a new event which references the old event it supersedes. As orders are immutable, the system has to keep track of which orders are still active and which are replaced.
Buy processing the order and execution streams, we can reconstruct the complete state of the exchange.
Obtaining the data
You can use the prepare.sh script from the examples repository to automatically download, extract, and preprocess the dataset:
git clone git@github.com:cedardb/examples.git
cd examples/nasdaq
./prepare.shIt downloads the dataset directly from NASDAQ. There is data for multiple full trading days (approx. one a year). We chose January 30, 2020 since it was the most busy and recent trading day available.
The data comes in the NASDAQ ITCH v5.0 protocol format:
$ hexdump -C -n 100 01302020.NASDAQ_ITCH50
00000000 00 0c 53 00 00 00 00 09 f6 49 c8 0c d3 4f 00 27 |..S......I...O.'|
00000010 52 00 01 00 00 0a 37 d4 c8 05 0b 41 20 20 20 20 |R.....7....A |
00000020 20 20 20 4e 20 00 00 00 64 4e 43 5a 20 50 4e 20 | N ...dNCZ PN |
00000030 31 4e 00 00 00 00 4e 00 27 52 00 02 00 00 0a 37 |1N....N.'R.....7|
00000040 d4 c9 da 87 41 41 20 20 20 20 20 20 4e 20 00 00 |....AA N ..|
00000050 00 64 4e 43 5a 20 50 4e 20 31 4e 00 00 00 01 4e |.dNCZ PN 1N....N|
00000060 00 27 52 00 |.'R.|
00000064We have written a Python parser to transform this into human readable CSV files.
It is automatically invoked by the prepare.sh script.
The schema
Here’s the corresponding SQL schema for the csv tables:
DROP TABLE IF EXISTS executions;
DROP TABLE IF EXISTS cancellations;
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS marketMakers;
DROP TABLE IF EXISTS stocks;
CREATE TABLE stocks
(
stockId int primary key,
name text unique,
marketCategory text,
financialStatusIndicator text,
roundLotSize int,
roundLotsOnly bool,
issueClassification text,
issueSubType text,
authenticity text,
shortSaleThresholdIndicator bool,
IPOFlag bool,
LULDReferencePriceTier text,
ETPFlag bool,
ETPLeverageFactor int,
InverseIndicator bool
);
CREATE TABLE marketmakers
(
timestamp bigint,
stockId int,
name text,
isPrimary bool,
mode text,
state text
);
CREATE TABLE orders
(
stockId int not null,
timestamp bigint not null,
orderId bigint primary key not null,
side text,
quantity int not null,
price numeric(10,4) not null,
attribution text,
prevOrder bigint
);
CREATE TABLE executions
(
timestamp bigint not null,
orderId bigint,
stockId int not null,
quantity int not null,
price numeric(10,4)
);
CREATE TABLE cancellations
(
timestamp bigint not null,
orderId bigint not null,
stockId int not null,
quantity int
);Loading the data
Let’s load the data into CedarDB:
\i schema.sql
\copy stocks from 'stocks.csv' DELIMITER ';' CSV NULL '' ESCAPE '\' HEADER;
\copy marketMakers from 'marketMakers.csv' DELIMITER ';' CSV NULL '' ESCAPE '\' HEADER;
\copy executions from 'executions.csv' DELIMITER ';' CSV NULL '' ESCAPE '\' HEADER;
\copy orders from 'orders.csv' DELIMITER ';' CSV NULL '' ESCAPE '\' HEADER;
\copy cancellations from 'cancellations.csv' DELIMITER ';' CSV NULL '' ESCAPE '\' HEADER;\copy is easy to use, but slow: It forces the client to serialize all data and send it to CedarDB over the network.
If we mount the data directly into the CedarDB docker container, we can considerably speed up the import process:
docker run --rm -p 5432:5432 -e CEDAR_PASSWORD=postgres -v /path/to/the/csvs:/data cedardb\i schema.sql
copy stocks from '/data/stocks.csv' DELIMITER ';' NULL '' ESCAPE '\' HEADER;
copy marketMakers from '/data/marketMakers.csv' DELIMITER ';' NULL '' ESCAPE '\' HEADER;
copy executions from '/data/executions.csv' DELIMITER ';' NULL '' ESCAPE '\' HEADER;
copy orders from '/data/orders.csv' DELIMITER ';' NULL '' ESCAPE '\' HEADER;
copy cancellations from '/data/cancellations.csv' DELIMITER ';' NULL '' ESCAPE '\' HEADER;This cuts the import time from ~3 minutes to 1 minute!
Queries
Let’s run some queries to gain some insight!
What was the price of one Apple share at end of day?
The canonical stock price is by definition the price of the last executed order, i.e. the price where the timestamp is the largest. Since executions usually don’t come with a price attached (except for some special cases), we have to look up the price in the matching order if it is null.
select arg_max(coalesce(e.price, o.price), e.timestamp) as price
from executions e, stocks s, orders o
where e.stockid = s.stockid
and e.orderid = o.orderid
and s.name = 'AAPL'; price
----------
323.5800
(1 row)
Time: 11.413 msHow many new orders in a trading day?
All orders that don’t supersede another order are new:
select count(*) as new from orders where prevOrder is null; new
-----------
181194793
(1 row)
Time: 28.361 msMost executions of a single order
An order can be executed multiple times (e.g., a market participant creates sell order for 1000 Apple shares which are then bought one by one by 1000 different buyers). Let’s print a histogram on how often orders are executed:
with executions_per_order as (
select orderid, count(*) as num from executions where orderid is not null group by orderid
)
select num as executions, count(*) from executions_per_order group by num order by num asc; executions | count
------------+---------
1 | 5575247
2 | 841766
3 | 203629
4 | 65619
5 | 25640
6 | 11436
7 | 5907
8 | 3347
9 | 1955
10 | 1272
<snip>
83 | 2
85 | 1
92 | 2
94 | 1
95 | 1
97 | 1
99 | 1
154 | 1
188 | 1
242 | 1
283 | 1
Time: 90.459 msQuite a long tail!
The 100 biggest trades
Let’s find the 100 trades with the most volume, calculated by price * quantity.
with priced_executions as(
select e.*, coalesce(e.price, o.price) as real_price
from orders o, executions e
where e.orderId = o.orderId)
select name as ticker, quantity, real_price as price, quantity*real_price as total
from priced_executions pe, stocks s
where pe.stockid = s.stockid
order by quantity * real_price desc limit 10; ticker | quantity | price | total
--------+----------+-----------+--------------
TSLA | 14549 | 647.0000 | 9413203.0000
AMZN | 4455 | 1860.5000 | 8288527.5000
TSLA | 9912 | 646.4900 | 6408008.8800
AVGO | 19744 | 315.0000 | 6219360.0000
TSLA | 10000 | 620.0000 | 6200000.0000
TSLA | 9189 | 644.0000 | 5917716.0000
AMZN | 2700 | 2039.7900 | 5507433.0000
AMZN | 2500 | 2028.7600 | 5071900.0000
TSLA | 7722 | 646.6700 | 4993585.7400
AMZN | 2465 | 2003.2500 | 4938011.2500
(10 rows)
Time: 716.949 msOrders that took the longest to be executed
Which market participants where the most patient? I.e., which order took the longest from being created to being executed without it being changed in between.
with exec_distance as (
select s.name as ticker,
o.side, coalesce(e.price, o.price) as price,
o.quantity as orderquant,
e.quantity as executedquant,
round((e.timestamp - o.timestamp) / (1000.0 * 1000 * 1000 * 60))::int as minutes
from orders o, executions e, stocks s
where o.orderId = e.orderId
and e.stockid = s.stockid
)
select *
from exec_distance
order by minutes desc limit 10; ticker | side | price | orderquant | executedquant | minutes
--------+------+---------+------------+---------------+---------
INO | SELL | 5.0400 | 1000 | 950 | 611
INO | SELL | 5.0000 | 100 | 100 | 605
ERIC | SELL | 8.0300 | 300 | 250 | 581
ZVZZT | BUY | 9.9900 | 100 | 100 | 578
ZVZZT | BUY | 9.9900 | 100 | 13 | 578
ZVZZT | BUY | 9.9900 | 100 | 87 | 578
ZVZZT | BUY | 9.9900 | 100 | 13 | 578
PS | SELL | 20.0600 | 100 | 10 | 577
INO | SELL | 5.0000 | 18 | 18 | 575
INO | SELL | 4.8800 | 4000 | 1000 | 569
(10 rows)
Time: 896.267 msPlot the trading activity
Let’s take a look at how the trading activity changes over the trading day.
We can use R with ggplot to generate a nice graph of all activity:
#!/usr/bin/Rscript
#install.packages(c("RPostgres", "ggplot2"))
library(RPostgres)
library(ggplot2)
# Connect to CedarDB
con <- dbConnect(RPostgres::Postgres(), host="localhost", user="postgres", password="postgres", dbname="postgres")
on.exit(dbDisconnect(con))
ordersHistogram <- dbGetQuery(con, "
with limits as (
select 34200000000000 as start, -- 9:30 AM (market open)
57600000000000 - 1 as end, -- just before 4:00 PM (market close)
60::bigint * 1000 * 1000 * 1000 as step -- bin size of 1 minute
), bins as (
select generate_series(l.start, l.end, l.step) as time
from limits l
), events as (
select timestamp, orderid, 'exec' as type from executions
union all
select timestamp, orderid, 'new' as type from orders where prevOrder is null
union all
select timestamp, orderid, 'update' as type from orders where prevOrder is not null
union all
select timestamp, orderid, 'cancel' as type from cancellations
), binned as (
select b.time, event.*
from limits l, bins b left outer join events event on (event.timestamp >= b.time
and event.timestamp < b.time + l.step )
)
select (time - start) / (step * 60.0) as hours, type, count(*) / 60 as eventspersecond
from binned, limits
group by hours, type
order by hours asc;
")
ggplot(ordersHistogram) + geom_line(aes(x=hours, y=eventspersecond, color=type))
ggsave("nasdaq.png", width = 8, height = 4.5, dpi = 200)We can now create the plot with Rscript nasdaq.R. This takes about 10 seconds to execute on a standard laptop:
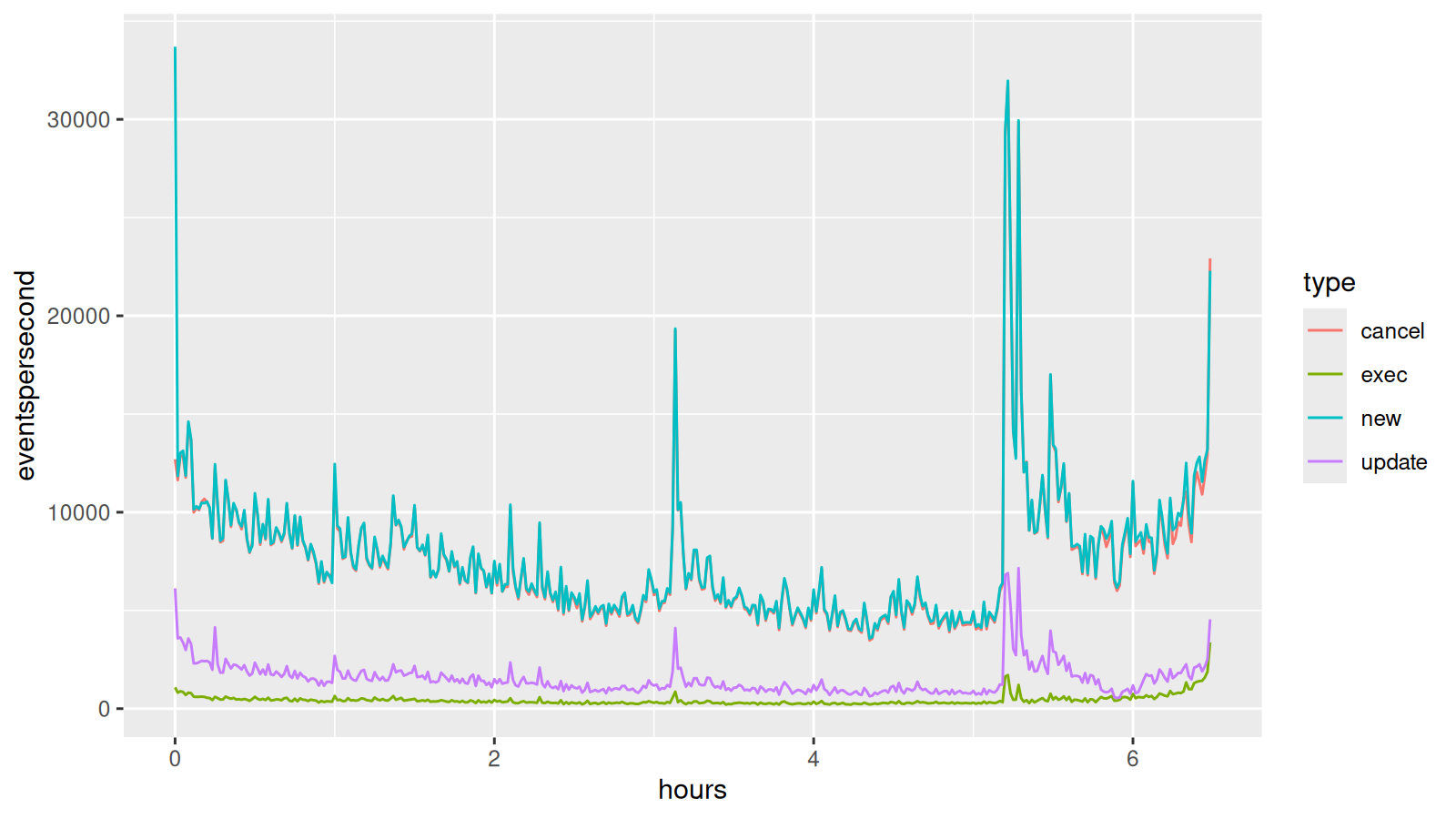
Interesting! Most orders are canceled and only a small part of all incoming orders are executed. Most market participants don’t seem to have an interest in their orders actually going through. An insight that wouldn’t have been possible with more coarse grained market data.
